
AI and Machine Learning Concepts - Part 2
AI Product Management: Neural Networks, Deep Learning Architectures, and Advanced AI/ML Concepts

Dear readers,
Thank you for being part of our growing community. Here’s what’s new this today,
AI Product Management:
AI and Machine Learning Concepts - Part 2 (Neural Networks, Deep Learning Architectures, and Advanced AI/ML Concepts)
Note: This post is for our Paid Subscribers, If you haven’t subscribed yet,

Table of Contents
Neural Networks: The Foundation of Deep Learning
Multilayer Perceptron (MLP)
Convolutional Neural Networks (CNN)
Recurrent Neural Networks (RNN)
LSTM (Long Short-Term Memory)
GRU (Gated Recurrent Unit)
Transformers
Generative Adversarial Networks (GAN)
Autoencoders
Radial Basis Function Networks (RBFN)
Neural Network Architecture Comparison
AI/ML Concepts Every PM Should Know
Transfer Learning
Fine-Tuning
Retrieval-Augmented Generation (RAG)
Embeddings
Overfitting and Underfitting
Bias-Variance Tradeoff
Feature Engineering
Explainable AI (XAI)
Federated Learning
AutoML (Automated Machine Learning)
MLOps (Machine Learning Operations)
Data Drift and Model Drift
Prompt Engineering
Hallucination
Tokenization
Reference Glossary
[Important] The PM’s Decision Framework: When to Use What?
Neural Networks: The Foundation of Deep Learning
Neural Networks are computational models inspired by the structure of the human brain. They consist of layers of interconnected nodes (neurons) that process information. Each connection has a weight that is adjusted during training. When a neural network has many layers, it is called a Deep Neural Network, and the field of training these networks is called Deep Learning.
Everyday Analogy
Think of a neural network like a company’s decision-making chain. An entry-level analyst (input layer) gathers raw data. Middle managers (hidden layers) process and interpret it at increasing levels of abstraction. The CEO (output layer) makes the final decision. Each person’s influence (weight) on the final decision is different, and the company gets better at decisions as people learn from outcomes over time.
Key Neural Network Vocabulary
Neuron/Node: A single computational unit that receives inputs, applies weights, adds a bias, and passes the result through an activation function.
Layer: A group of neurons. Input layer receives data, hidden layers process it, output layer produces the result.
Weights: Numbers that determine how much influence one neuron has on the next. Adjusted during training.
Bias: An extra parameter that shifts the activation function, giving the model flexibility.
Activation Function: A mathematical function (like ReLU or Sigmoid) that introduces non-linearity, allowing the network to learn complex patterns.
Backpropagation: The algorithm that calculates how to adjust weights by propagating errors backward through the network.
Epoch: One complete pass through the entire training dataset.
Learning Rate: How much weights are adjusted in each training step. Too high and the model overshoots; too low and it learns too slowly.
Multilayer Perceptron (MLP)
What it is: The MLP is the simplest form of a feedforward neural network. Data flows in one direction: from input layer, through one or more hidden layers, to the output layer. Every neuron in one layer connects to every neuron in the next layer (fully connected). MLPs are the building block upon which all other neural network architectures are based.
Example: Demand Prediction
Your product team needs to predict daily active users for capacity planning. The MLP takes inputs like day of week, marketing spend, recent feature launches, and seasonality indicators. Hidden layers learn complex interactions between these factors (e.g., marketing spend matters more on weekdays). The output layer produces a single number: predicted DAU for tomorrow.
When to Use MLP vs. Other Architectures
Use MLP for structured/tabular data (spreadsheet-like data with rows and columns).
Use CNN for image, video, or spatial data.
Use RNN/Transformers for sequential data (text, time series).
MLP is a great starting point, but specialized architectures will outperform it on their respective data types.
Convolutional Neural Networks (CNN)
What it is: CNNs are specialized neural networks designed for processing grid-structured data, especially images. Instead of connecting every neuron to every input (like an MLP), CNNs use small filters (kernels) that slide across the input to detect local patterns like edges, textures, and shapes. Deeper layers combine these simple patterns into complex features.
Everyday Analogy
Imagine examining a photograph with a magnifying glass. You scan small regions at a time, noting patterns: ‘Here is an edge,’ ‘Here is a curve,’ ‘Here is a texture.’ Then you zoom out and combine those observations: ‘Those edges and curves form an eye,’ then ‘That eye plus a nose plus a mouth form a face.’ CNNs work exactly this way, building from local details to global understanding.
CNN Architecture Components
Convolutional Layer: Applies filters to detect local features (edges, colors, textures).
Pooling Layer: Downsamples feature maps to reduce size and computation (e.g., Max Pooling keeps the strongest signal in each region).
Flatten Layer: Converts 2D feature maps into a 1D vector for the final classification layers.
Fully Connected Layer: Standard neural network layer that makes the final prediction based on extracted features.
Example: Visual Search in E-commerce
Your e-commerce app lets users upload a photo of a product they like, and the CNN identifies similar items in your catalog. The convolutional layers detect visual features: color palette, shape outline, texture pattern. Deeper layers recognize higher-level features: ‘round sunglasses,’ ‘floral pattern dress,’ ‘leather crossbody bag.’ The final layer matches these features against your product database to show visually similar items.
Recurrent Neural Networks (RNN)
What it is: RNNs are designed for sequential data where order matters. Unlike feedforward networks, RNNs have loops that allow information from previous steps to influence the current step. This gives them a form of ‘memory’ that is essential for processing text, speech, time series, and any data where context from earlier in the sequence is important.
Everyday Analogy
Reading a sentence is sequential. When you read the word ‘bank,’ its meaning depends on what came before: ‘river bank’ vs. ‘savings bank.’ Your brain carries context from earlier words. RNNs do the same thing: each step processes the current input while incorporating a summary of everything that came before.
The Vanishing Gradient Problem
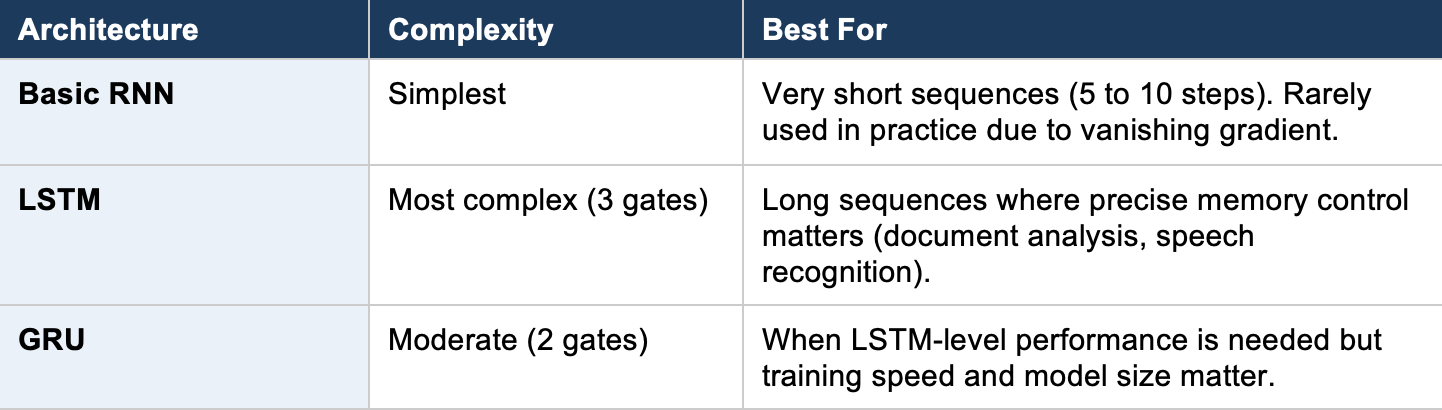
Basic RNNs struggle with long sequences because the ‘memory’ signal weakens as it passes through many steps (like a game of telephone where the message gets garbled). This is called the vanishing gradient problem. LSTM and GRU were invented to solve this.
1. LSTM (Long Short-Term Memory)
What it is: LSTM is an advanced RNN architecture with a sophisticated gating mechanism that controls what information to remember, what to forget, and what to output at each step. It has three gates: a forget gate (what to discard), an input gate (what new information to store), and an output gate (what to pass to the next step).
Example: Customer Support Ticket Routing
A customer writes a long support message describing their issue. The LSTM reads it word by word. The forget gate discards pleasantries (’Hi, hope you are well’). The input gate stores key information (’billing error,’ ‘charged twice,’ ‘premium plan’). The output gate produces a classification: route to the Billing team with ‘Priority: High.’ It understands context across the entire message, not just individual keywords.
2. GRU (Gated Recurrent Unit)
What it is: GRU is a simplified version of LSTM that combines the forget and input gates into a single ‘update gate’ and merges the cell state with the hidden state. It has fewer parameters than LSTM, making it faster to train while achieving comparable performance on many tasks.
Example: Real-Time Session Analysis
You want to predict user intent during a live session. GRU processes the stream of user actions (click, scroll, search, add-to-cart) in real time. Its simpler architecture means faster inference, which matters when you need to serve personalized content within milliseconds. If the sequence suggests purchase intent, you trigger a discount popup before the user leaves.
Transformers
What it is: Transformers are the architecture behind virtually all modern large language models (ChatGPT, Claude, Gemini, LLaMA). Their key innovation is the ‘self-attention mechanism,’ which allows the model to look at all parts of the input simultaneously rather than processing it sequentially like RNNs. This parallel processing makes Transformers dramatically faster to train and better at capturing long-range relationships.
Everyday Analogy
Imagine reading a legal contract. An RNN reads word by word from start to finish. A Transformer is like having a team of lawyers who each read the entire document simultaneously, with each lawyer paying special attention to different clauses and cross-referencing them. They then combine their analyses. This parallel, cross-referencing approach is why Transformers excel at understanding context.
Key Transformer Concepts
Self-Attention: Each word calculates how much it should ‘pay attention’ to every other word in the sequence. The word ‘it’ in ‘The cat sat on the mat because it was tired’ attends strongly to ‘cat.’
Multi-Head Attention: Multiple attention mechanisms run in parallel, each learning different types of relationships (syntactic, semantic, positional).
Positional Encoding: Since Transformers process all words simultaneously (not sequentially), they add position information so the model knows word order.
Encoder: Processes the input and creates a rich representation (used in models like BERT for understanding tasks).
Decoder: Generates output token by token (used in models like GPT for generation tasks).
Encoder-Decoder: Full architecture used for translation and summarization (the original Transformer design).
Example: AI-Powered Product Features
Transformers power features your users interact with daily: smart search that understands natural language queries (’show me red dresses under $50 with free shipping’), chatbots that maintain context across long conversations, auto-generated product descriptions, code completion tools, and document summarization. Understanding Transformers helps you evaluate vendor claims, estimate compute costs, and set realistic expectations for AI-powered features.
Generative Adversarial Networks (GAN)
What it is: A GAN consists of two neural networks competing against each other. The Generator creates fake data (images, text, audio) trying to fool the Discriminator. The Discriminator tries to distinguish real data from fake. This adversarial training pushes both networks to improve until the Generator produces data so realistic that the Discriminator cannot tell the difference.
Everyday Analogy
Think of an art forger (Generator) and an art detective (Discriminator). The forger creates fake paintings. The detective tries to identify fakes. Each time the detective catches a fake, the forger learns to make better copies. Each time the forger fools the detective, the detective gets better at spotting fakes. After thousands of rounds, the forger produces nearly perfect replicas.
Example: Synthetic Data Generation
Your product team needs to test a new feature with realistic user data, but privacy regulations prevent using real customer data. A GAN trained on anonymized patterns of your user behavior generates synthetic but statistically realistic user profiles, transaction histories, and interaction logs. The synthetic data preserves the statistical properties of real data without containing any actual customer information, enabling thorough testing without privacy risk.
Autoencoders
What it is: An Autoencoder is a neural network trained to compress data into a smaller representation (encoding) and then reconstruct the original data from that compression (decoding). The compressed representation in the middle (called the latent space or bottleneck) captures the most essential features of the data.
Everyday Analogy
Imagine summarizing a 300-page book into a 5-page executive brief (encoding), then asking someone to reconstruct the full book from just the brief (decoding). The brief must capture the essential plot, characters, and themes. The better the brief, the more accurately someone can recreate the original story. The brief is the latent representation.
Example: Anomaly Detection in User Behavior
You train an autoencoder on normal user session data. The model learns to compress and reconstruct typical behavior patterns. When a compromised account exhibits unusual behavior (rapid API calls, unusual data access patterns), the autoencoder fails to reconstruct it accurately. The high reconstruction error signals an anomaly, triggering a security alert.
Radial Basis Function Networks (RBFN)
What it is: RBF Networks are a type of neural network that uses radial basis functions (typically Gaussian bell curves) as activation functions. The hidden layer measures how close the input is to a set of center points. Inputs near a center activate strongly; distant inputs activate weakly. This makes RBFNs excellent for pattern recognition and interpolation.
Example: Location-Based Service Quality
You are monitoring service quality across geographic regions. Each RBF neuron represents a service center location. When a user reports an issue, the network evaluates how close the report is to known problem centers (both geographically and in terms of issue type). Reports near known problem clusters receive faster response routing. Reports far from any known cluster indicate a potential new issue pattern.
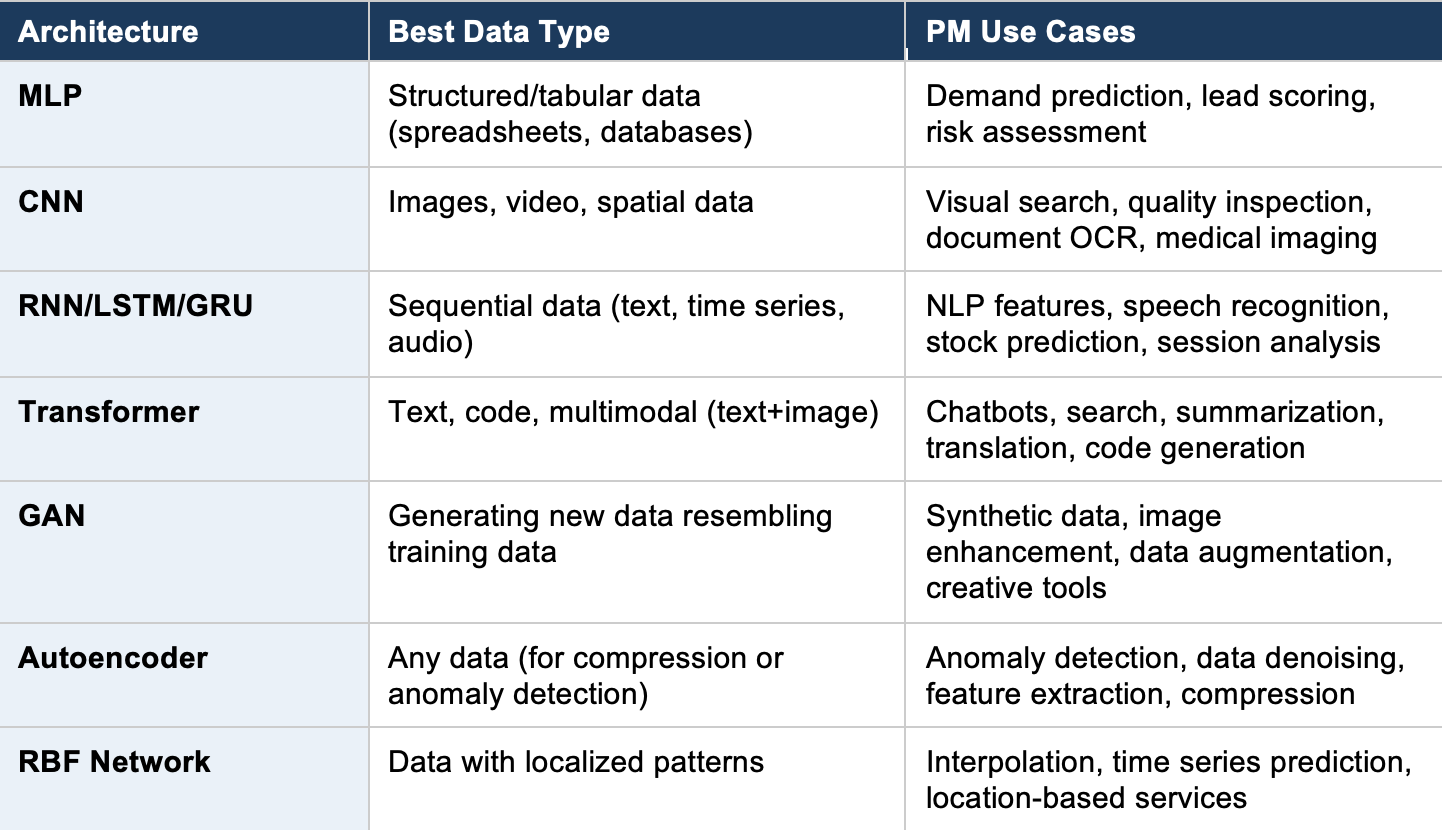
Neural Network Architecture Comparison
The following table summarises when to use each neural network architecture:
AI/ML Concepts Every PM Should Know
Beyond the core algorithms, several advanced concepts are increasingly important for product managers building AI-powered products. This section covers the terms you will encounter in conversations with your ML engineering team.
